Introducing the Integrated Accelerator for Z Sort
Sort processing has long been an integral part of enterprise workloads. There are many applications: batch sort, database query processing, database reorganization, and analytics, to name a few. Based on our analysis of customer data, it’s not uncommon for an IBM Z customer to sort dozens of terabytes of data weekly. As the amount of data increases over time, so does the elapsed time and CPU time required to sort the data.
IBM Z has supported sort for a long time now with the z/Architecture instructions “COMPARE AND FORM CODEWORD” and “UPDATE TREE”. These instructions address aspects of the sort and merge process, such as comparing two elements and adding an element to a tree, but they rely on software to implement the bulk of the algorithm (Reference: IBM z/Architecture Principles of Operation Appendix A, page A-53).
The z15 approach is a new coprocessor called the Integrated Accelerator for Z Sort, which is driven by the new SORT LISTS (SORTL) instruction. z/OS DFSORT takes advantage of Z Sort, providing users with significant performance boosts for their sort workloads.
With z/OS DFSORT's new Z Sort algorithm, clients can see batch sort job elapsed time improvements of up to 20–30% depending on record size and CPU time improvements of up to 40% compared to z14.*
This capability is available now on z15 with z/OS DFSORT APAR PH03207, PTFs UI90067, and UI90068 for z/OS V2R3 and V2R4.
SORTL and the Hardware
SORT LISTS (SORTL) is a z15 problem state instruction that can turn up to 128 lists of unsorted input data into one or more lists of sorted output data. It also provides a means to merge multiple lists of sorted-input data into a single list of sorted-output data. Therefore, two modes of operation are supported: sort mode and merge mode. Merge mode is slightly more efficient because it takes advantage of the input lists being sorted already.
When invoking the SORTL instruction, the calling program specifies the locations and sizes of the input lists, the locations and sizes of the output buffers, and the sizes of the key and payload portions of the records in all lists to be processed.
There is practically no limit to the amount of data that could be processed with a single call to SORTL under the right conditions. SORTL can run for a very long time; however, in a typical program, it is expected that external interrupts (i.e., page fault, time slice exceeded) will force the instruction to stop before it is completely done. In that case, instruction execution is suspended, the current state is stored in the parameter block, the processor registers that specified the output buffers and lengths are updated, and an appropriate condition code is set. The program is expected to branch back to the sorting instruction upon inspecting that condition code. Execution will then continue from where it was interrupted.
Under the covers, firmware and dedicated hardware work together to deliver a very efficient sorting capability. The sort accelerator is part of the processor core and runs at the same frequency. Data is transferred to and from the accelerator using the private L1 and L2 CPU caches.
z/OS DFSORT Z Sort Algorithm and Performance Considerations
With the ability of SORTL to accept many input lists in a single invocation — and the sort accelerator’s low latency access to data in CPU caches — the primary limitations become just how quickly the program can stage data in and out of memory (think of reading and writing data from data sets on DASD), and how much memory the program is permitted to use.
DFSORT introduced a new sort algorithm, which not only exploits the Integrated Accelerator for Z Sort but also contains I/O optimizations, increased parallelism, and leverages 64-bit pageable large pages in order to maximize the rate at which data can be delivered to the sort accelerator.
With regard to sort performance, both CPU and elapsed time savings are heavily influenced by the record length because it dictates how much data must be read/written to disk or copied into memory for each record.
Referring to the chart below, which is available in the DFSORT User’s Guide for PH03207, the elapsed time percent benefit is higher for smaller records because fewer bytes per record must be moved. More records can be read or written at once and are delivered to the sort accelerator more quickly. The time spent sorting rather than waiting for I/O is more significant. The sorting is made more efficient, resulting in larger elapsed time savings.
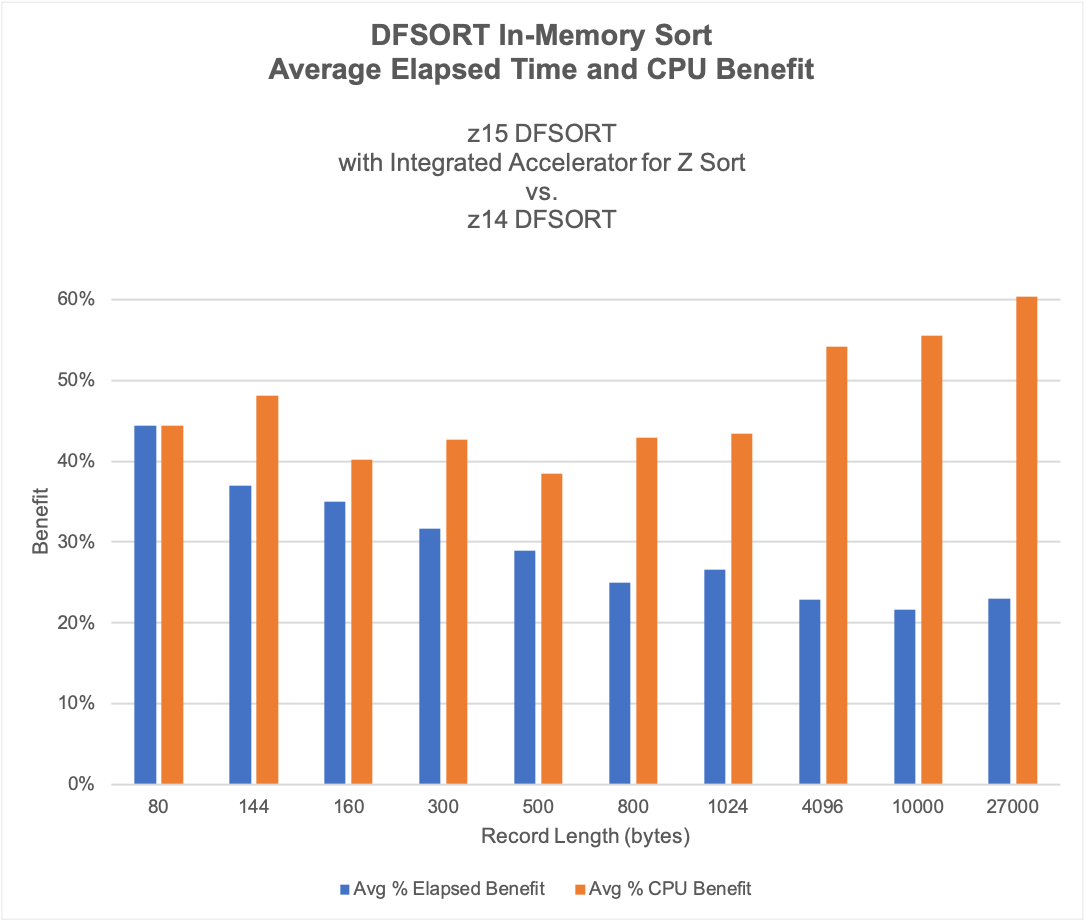
As the record size increases, the sorting to I/O latency ratio decreases. Even though the sort accelerator is more CPU efficient, the I/O latency is driving a larger portion of the total elapsed time. As a result, the elapsed time percentage benefit decreases for large records.
Clients can realize the most benefit from Z Sort in an unconstrained environment, particularly when it comes to memory. Z Sort is designed to take advantage of large memory. The following parameters determine how much 64-bit memory DFSORT can use:
- The DFSORT MOSIZE keyword, which lets the user override the size of the 64-bit memory object obtained by DFSORT
- The JCL MEMLIMIT keyword, which limits 64-bit virtual memory at the job or job step level. REGION value is used for MEMLIMIT if not specified elsewhere
- The SMFPRMxx PARMLIB member, which allows one to set a system-wide default MEMLIMIT
- The IEFUSI Exit Interface, which also can set a system-wide default MEMLIMIT
- How much memory is available on the system at the time of execution
We have seen from several clients’ data that many of the sort jobs sort files under 100 GB in size. Be sure you allow DFSORT to utilize large memory for your sort workload.
How to Leverage DFSORT Z Sort in Your Shop
Z Sort is easy to enable at the job step or system level by specifying the OPTION ZSORT keyword in your DFSORT control statements, ICEMAC, or ICEPRM PARMLIB member.
There are some more complicated sort control statements that are not Z Sort compatible. In such an event, DFSORT automatically switches to the non-Z Sort path, logs the event in the job message output, and continues as normal. Some other prerequisites are using BSAM for Sort Input/Output and Z High Performance FICON (zHPF), which also improve I/O efficiency. A full list of requirements can be found in the DFSORT PH03207 Users’ Guide.
The Z Batch Network Analyzer (zBNA) tool, a free utility available from IBM has been updated with a new Z Sort feature, which helps to show eligible jobs and estimate elapsed and CPU time benefits from Z Sort. Be sure to download zBNA and see how your workloads can benefit.
Additionally, the Db2 for z/OS REORG utility has been enhanced to leverage DFSORT Z Sort with APAR PH28183, PTF UI71668 for Db2 V12. With this support, clients can see an elapsed time benefit of up to 12% and a CPU time benefit of up to 19% versus z14.**
References
Disclaimers
*Performance results based on IBM internal tests performed on dedicated z15 and z14 environments running DFSORT in-memory sort jobs using 64-bit memory objects. DFSORT work was eligible for Integrated Accelerator for Z Sort exploitation on z15. Results based on averages of the elapsed time and CPU benefit measured over a range of dataset record lengths (80 bytes – 27K bytes), key sizes (8-500 bytes), number of records (100K -100M), and record formats (fixed block and variable block) with large format and extended format data sets. Results may vary.
**Performance results based on IBM internal tests performed on dedicated z15 and z14 environments running Db2 12 for z/OS REORG utility jobs that invoke DFSORT. DFSORT work was eligible for Integrated Accelerator for Z Sort exploitation on z15. Db2 REORG utility is performed as SHRLEVEL CHANGE against the partitioned table space with 20 partitions using up to 20 parallel tasks. The table space is compressed and the index spaces are not compressed. The average record length is 243 bytes and the record contains 15 VARCHAR columns with key length from 33 to 165 bytes. There are two user indexes defined, one partitioned index, one non-partitioned index against the table. The table contains 100 million rows and loaded with random order against the clustering index prior to REORG execution. The z/OS LPARs were configured with 4 general purpose processors, 1 zIIP and 512GB of real memory in both z14 and z15 measurements. For all measurements, sorts were done in 64-bit memory objects exclusively. When the Integrated Accelerator for Z Sort is utilized on z15, up to 2 times as much 64-bit memory may be used compared to z14. Results may vary based on various factors including, the number of rows, row size, key size, compression option, dictionary option, available real storage that DFSORT can utilize, and the number of processors.